Partition Demystified
Following my system design blogs, this is another blog where we will learn about "partition". In the last blog we learned about Sharding.
We will pick the same problem as we picked in sharding.
Problem
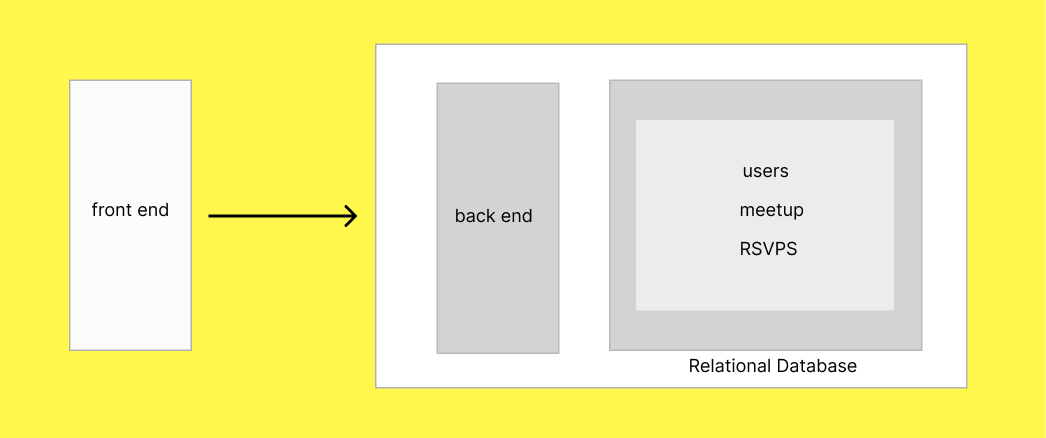
Imagine you’ve built a Meetup-style web application. Users can register, browse events, and RSVP to the ones they’re interested in. Initially, everything runs smoothly, the platform uses a single relational database like PostgreSQL or MySQL, and the traffic is manageable.
But soon, your platform takes off. The user base grows rapidly. Now, thousands of users are:
1 . Creating and updating profiles
2 . Browsing through hundreds of upcoming events
3 . Sending RSVPs in real time
As a result, you start noticing signs of stress in your backend:
1 . Fetching meetups takes longer than expected
2 . RSVP actions are delayed or time out
3 . Pages load slowly, especially during peak hours
On deeper inspection, you identify the core issues:
1 . Heavy read/write patterns on the same database tables (users, meetups, RSVPs)
2 . Query latency growing with data size; as rows pile up, indexes become bloated and less efficient
3 . Write contention on hot tables like RSVPs
4 . Disk IOPS and CPU usage on your database instance hitting their limits
It’s clear that your single-database setup isn’t scaling well. You need to rethink how your data is stored and accessed — in a way that distributes the load, reduces contention, and keeps performance fast and consistent as you grow.
In the last blog we saw how sharding will solve this problem. In this blog we will explore partition.
Partition
Partitioning is the process of dividing a large database table into smaller, more manageable pieces, called partitions, all residing on the same server or logical database.
Each partition acts like a mini-table. When a query runs, the database can target only the relevant partition, reducing scan size and improving performance.
Think of it like slicing a big cake: instead of searching for a cherry in the whole cake, you can go directly to the right slice.
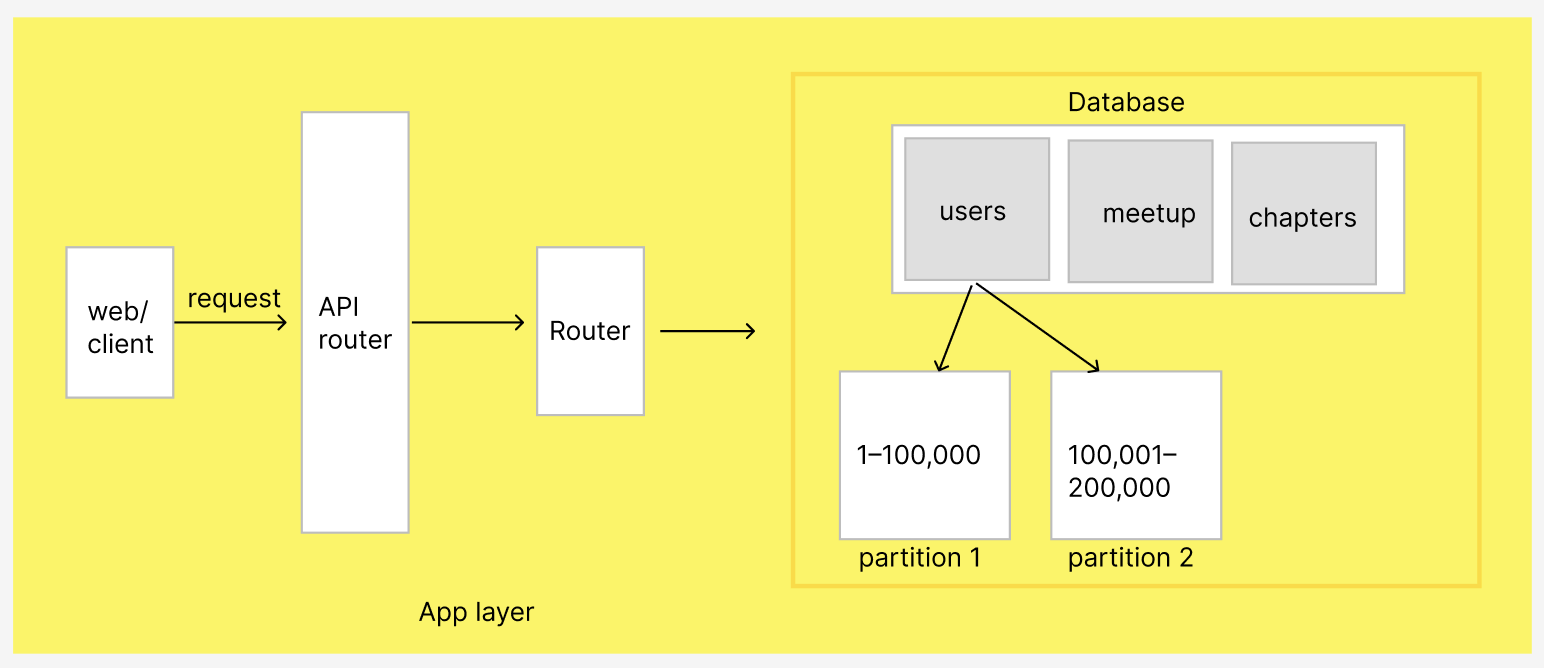
Eg: Let’s say your users table contains 10 million rows. You can partition it by user ID:
-
Partition 1: user_id 1–100,000
-
Partition 2: user_id 100,001–200,000
... and so on.
Now, a query for user_id = 150,000 directly targets Partition 2, skipping the rest.
Without partitioning, the database has to scan the entire users table or rely on large indexes, which becomes inefficient as the table grows.
partitioning should be driven by your access patterns, data growth rate, and performance bottlenecks.
Advantages of Partition
1 . Improved Query Performance : Partition allows the database engine to search only the relevant partitions.Reduces I/O overhead, improving response times for both reads and writes.
2 . Ease of Maintenance : You can drop or archive old partitions without locking the main table. Maintenance tasks like index rebuilding or vacuuming can target individual partitions.
3 . Security : You can set permissions at the partition level (in some DBMS), which helps in multi-tenant or regulated environments.
4 . Data Lifecycle Management : Time-based partitions make it easy to manage data retention policies. Example: drop all events older than a year by simply dropping a partition.
Types of Partitions
1 . Range : Split data by a continuous range of values. eg: created_at column for time-based data, or userID.
2 . List : Split based on specific values. eg: region field
3 . Hash : Uses a hash function to evenly distribute rows across partitions. Good for load balancing when there’s no natural range. eg: hash(user_id) % 4 → partitions 0, 1, 2, 3
4 . Composite Partitioning (Hybrid) : Combine two strategies, e.g., range + hash.
Magic Pill?
Partition is not a magic pill. Remember, designing system is all about trade-offs
1 . Increased complexity in schema design
2 . Queries across partitions may still require full scans or unions
3 . Foreign key constraints are often not supported across partitions (in systems like PostgreSQL)
How to do partition?
This is not prod ready code
// PostgreSQL
CREATE TABLE users (
id INT,
name TEXT,
created_at DATE
) PARTITION BY RANGE (id);
CREATE TABLE users_p1 PARTITION OF users FOR VALUES FROM (1) TO (100001);
CREATE TABLE users_p2 PARTITION OF users FOR VALUES FROM (100001) TO (200001);
Summary
Partitioning is a powerful way to scale a single-node database by splitting large tables into manageable chunks. It improves performance, simplifies maintenance, and helps with data lifecycle management.
Sharding, on the other hand, distributes the entire dataset across multiple databases — useful for global-scale systems but significantly more complex.
Next, read about sharding vs partition
Happy Learning!!