Sharding Demystified
Following my system design blogs, this is another blog where we will learn about "sharding vs partition".
A lot of folks assume that sharding and partition are same but they are not. When working with distributed systems, with data intensive applications, and data these 2 concepts will come handy.
To understand sharding and partition, we will look into a problem and then see how and where these will help.
This is a
two-partthree part blog series. In this post, we’ll focus on sharding, in the second post, we’ll learn about partitioning and in the last sharding vs parition
Problem
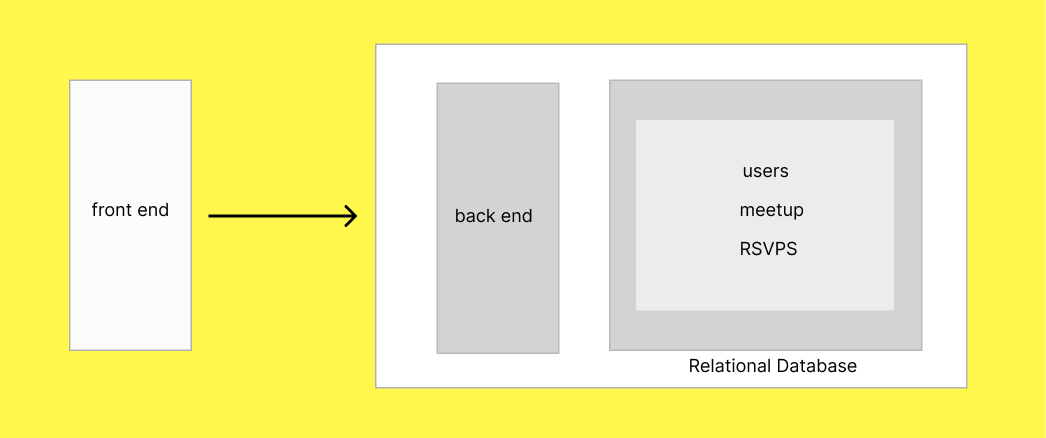
Imagine you’ve built a Meetup-style web application. Users can register, browse events, and RSVP to the ones they’re interested in. Initially, everything runs smoothly, the platform uses a single relational database like PostgreSQL or MySQL, and the traffic is manageable.
But soon, your platform takes off. The user base grows rapidly. Now, thousands of users are:
1 . Creating and updating profiles
2 . Browsing through hundreds of upcoming events
3 . Sending RSVPs in real time
As a result, you start noticing signs of stress in your backend:
1 . Fetching meetups takes longer than expected
2 . RSVP actions are delayed or time out
3 . Pages load slowly, especially during peak hours
On deeper inspection, you identify the core issues:
1 . Heavy read/write patterns on the same database tables (users, meetups, RSVPs)
2 . Query latency growing with data size; as rows pile up, indexes become bloated and less efficient
3 . Write contention on hot tables like RSVPs
4 . Disk IOPS and CPU usage on your database instance hitting their limits
It’s clear that your single-database setup isn’t scaling well. You need to rethink how your data is stored and accessed — in a way that distributes the load, reduces contention, and keeps performance fast and consistent as you grow.
Solution
To fix the above issues, partitioning and sharding come in. In this blog we will explore sharding.
Sharding
Sharding is a process of splitting a large database into smaller, independent pieces called shards, which are distributed across multiple servers. Each shard contains a subset of the data. A shard key determines how the data is distributed.
This enables horizontal scaling, allowing the system to handle more traffic and larger datasets by adding more servers.
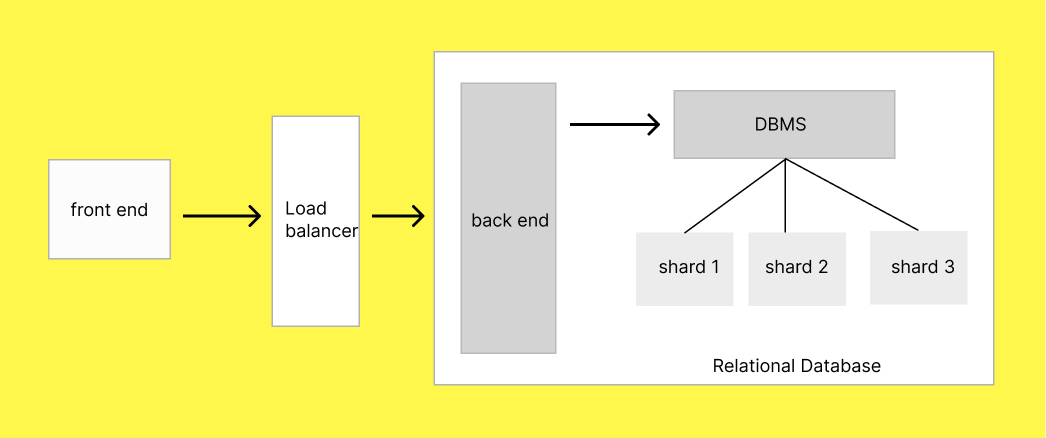
Advantages of Sharding:
1 . Scaling : Sharding is "horizontal scaling". It helps in scaling the system well as the shard are distributed across multiple servers.
2 . Fault tolrance : If one shard fail then this failure won't affect the other shards. The system will continue working as expected and this helps ensure fault tolrance. A trait every architecture should have.
3 . Performance : As the data is spread across multiple shard and servers the performance of query is improved and it also reduce the risk of "hot spots".
4 . Supports High Concurrency : Each shard can process queries independently.
5 . Tailored Data Placement : Shard based on geography, tenant, or access patterns
Types of shard:
| Type | What? | |
|---|---|---|
| 1 | Range based | Data is divided based on a continous range of values of the shard key. Eg: users of meetups from IDs 1–100 go to shard A, and so on. |
| 2 | Geo Based | Data is sharded based on a business rule or real-world division. Eg: users in the USA will go to shard A, users from Asia to shard B and so on. |
| 3 | Hash based | A hash function is applied to the shard key, and the result determines the shard: hash(user_id) % number_of_shards |
| 4 | Directory based | A central lookup table maps each key to a specific shard. Eg: The system maintains a table like user_id → shard_id. |
| 5 | Featured based | Data is divided based on the feature. |
Magic Pill?
Sharding is not the magic pill that will solve all the problems. It comes with a few dis-advantages. basically "trade-offs". In our meetup problem, Sharding by region helps scale: US → Shard A, EU → Shard B.But users attending events across regions may face latency or cross-shard lookups.
1 . Operational Complexity : More moving parts: monitoring, backups, and deployments become more complicated.
2 . Data Complexity : Handling data in sharding is complex as compare to non-sharding solution. You need to get the data and store them to correct shard, as well as manage retrieve the data too.
3 . Re-sharding : If you have to re-shard then it will be another complexity
4 . cross shard queries : Queries between shards are not easy. Joins, aggregations, and transactions across shard are difficult and slower.
5 . Inconsistent Load Distribution : Poor shard key choice can lead to "hot shards" with unequal load.
Data consistency and sharding
With sharding, we are distrubtuing, storing, and retrieving data from multiple shards distributed across multiple servers. This leads us to question - "How the data consistency will be? - Strong, weak, or eventually".
In sharding, we will have the eventual consistency
How to shard?
Now that we know what sharding is, trade-offs, types time to learn about how to do sharding. For our meetup problem, let's start with:

1 . Understand the Data and Workload : Which table is large, and gets high read/write. Eg: in Meetup table is it users, rsvps, meetups.
2 . Choose a Shard Key : Time to choose a shard key, this determines how data is distributed. It is important to identify the shard key which evenly distributes load, High cardinality (lots of unique values), meet most common query patterns. Eg: users -> user_id , meetups -> location or organizer_id
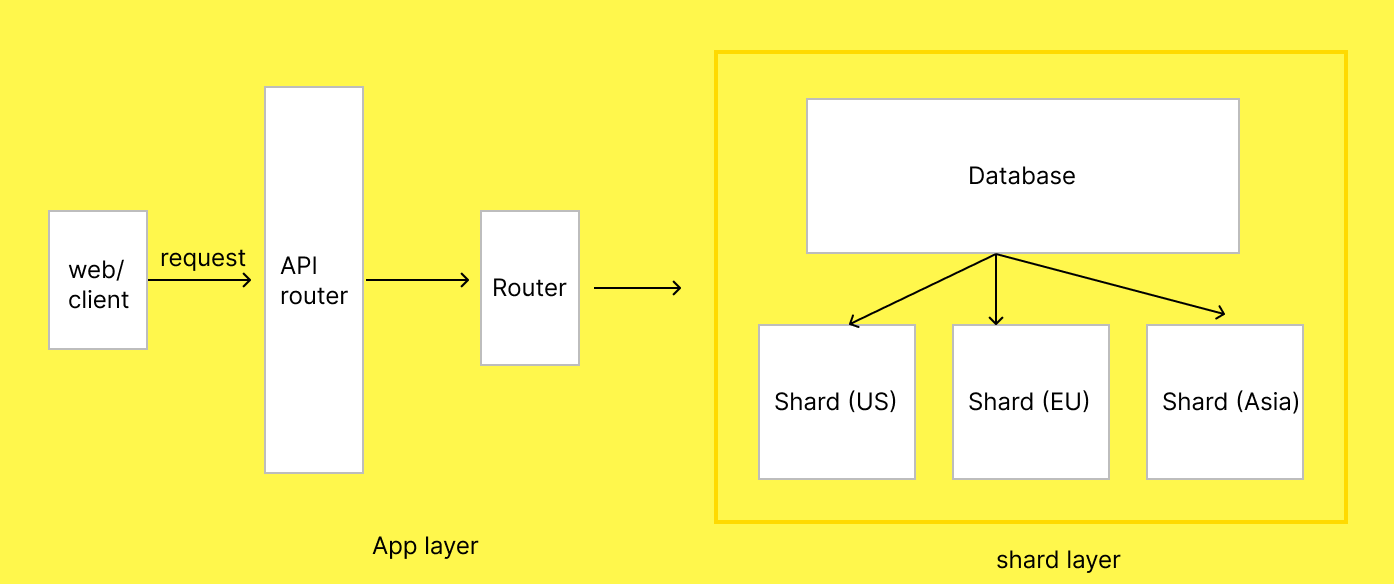
3 . Pick a Sharding Strategy : what should the sharding strategy be? In our case, we can go with the Geo-based sharding. Eg: when user logs in app identifies user’s region, Routes requests to the correct shard and all operations (fetch meetups, RSVP, etc.) to that shard. Eg: User from USA will go to shard A (having USA data).
4 . Update Application Logic : This is where the code will go. Writing Route requests, handle cross-shard queries, etc.
Once your data is sharded, another important task to take care who decides where the data goes: client (backend application) or server?
| Type | What? | |
|---|---|---|
| 1 | client side | The client (usually backend application) contains the logic to determine which shard to read/write from. |
| 2 | server side | The server (or middleware/proxy) handles which shard stores or retrieves data, abstracting this away from the client.Eg: AWS aurora with global DB, MongoDB (mongos router), Vitess etc. |
Setup: Code Time
PS: The below code examples are only for understanding the sharding concept. These are not "prod ready" code.
Shard config
A configuration file that contains the database connection string against the region. Horizontal scaling is possible (add more regions as shards grow)
// shard-config.js
export const shardMap = {
US: {
name: 'Shard A',
connectionString: 'postgres://user:pass@shard-us.example.com/meetupdb',
},
EU: {
name: 'Shard B',
connectionString: 'postgres://user:pass@shard-eu.example.com/meetupdb',
},
ASIA: {
name: 'Shard C',
connectionString: 'postgres://user:pass@shard-asia.example.com/meetupdb',
},
};
Shard Router
Router will be responsible for routing the users to the correct shard. Queries are routed only to relevant shards, reducing latency.
// db-router.js
import { shardMap } from './shard-config.js';
import { Client } from 'pg';
export function getShardClient(region) {
const shard = shardMap[region];
if (!shard) throw new Error(`No shard found for region: ${region}`);
const client = new Client({ connectionString: shard.connectionString });
return client;
}
RSVP
// rsvp.js
import { getShardClient } from './db-router.js';
export async function rsvpToMeetup(region, userId, meetupId) {
const client = getShardClient(region);
await client.connect();
await client.query(`
INSERT INTO rsvps (user_id, meetup_id) VALUES ($1, $2)
`, [userId, meetupId]);
await client.end();
console.log(`User ${userId} RSVPed to meetup ${meetupId} in ${region}`);
}
Tools for Sharding
1 . Vitess (Sharding layer for MySQL)
2 . MongoDB (Built-in sharding)
3 . Citus (Scalable Postgres with sharding)
4 . ProxySQL (MySQL routing/sharding proxy)
How sharding solves our problem?
After implementing sharding in our meetup project we can see the following improvements:
1 . Performance improvement
2 . Low latency
3 . Scaling
4 . Fault tolrance (no SPoF)
Summary
1 . Sharding = Data Splitting across multiple databases to handle scale, performance, and fault tolerance.
2 . It's not the same as partitioning—sharding involves physical distribution.
3 . Sharding improves scalability but adds complexity in querying, consistency, and rebalancing.
4 . Choosing the right shard key is critical—aim for high cardinality and balanced access patterns.
5 . Common strategies include geography-based, tenant-based, or feature-based sharding.
6 . Be aware of challenges like cross-shard queries, re-sharding, and operational overhead.
7 . Use sharding only when needed—it's powerful, but not a silver bullet.
Congrats!! you have reached to the end of the blog. If you liked this blog, found a mistake, or just want to say hi then do reach me at my socials.
Happy Learning!!