Database Replication Strategies
In large-scale, high-traffic applications, scaling the database layer is crucial for performance, fault tolerance, and availability. One of the core techniques used to achieve this is database replication—the process of copying and maintaining database objects (like records and schemas) in multiple database servers.
At its core, databases handle two types of operations:
- Write operations: Modifying or inserting new data.
- Read operations: Fetching or querying existing data.
To manage these efficiently under load, replication allows writes to go to one or more write nodes (leaders) and reads to be served from read-only replicas (followers).
Why Do We Need Database Replication?
As applications scale, relying on a single database node can lead to performance bottlenecks, single points of failure, and latency issues for global users. Replication addresses these challenges by distributing data across multiple nodes.
1 . Key Reasons for Replication: High Availability & Fault Tolerance If one node fails, others can take over seamlessly, ensuring the application remains operational.
2 . Read Scalability Read-heavy applications benefit from offloading traffic to replicas, reducing latency and improving throughput.
3 . Geo-Distributed Access Place replicas closer to end users to minimize latency and enhance performance for global audiences.
4 . Backup & Recovery Replicated data can act as live backups, enabling faster disaster recovery and business continuity.
5 . Analytics and Reporting Heavy analytical queries can be run on replicas, preventing slowdowns on the primary write node.
Pros and Cons of Replication:
It is not like that replication has no cons. There are reasons for using replication but there are a few trade offs too:
Pros:
1 . Improved Read Performance
2 . Fault Tolerance
3 . Horizontal Scalability for Reads
4 . Redundancy and Backup
5 . Lower Latency for Global Users
Cons
1 . Replication Lag: Followers might not have the most recent data.
2 . Conflict Resolution Complexity: Especially in multi-leader and leaderless setups.
3 . Operational Overhead: More infrastructure and management required.
4 . Eventual Consistency Risks: Temporary inconsistencies are possible.
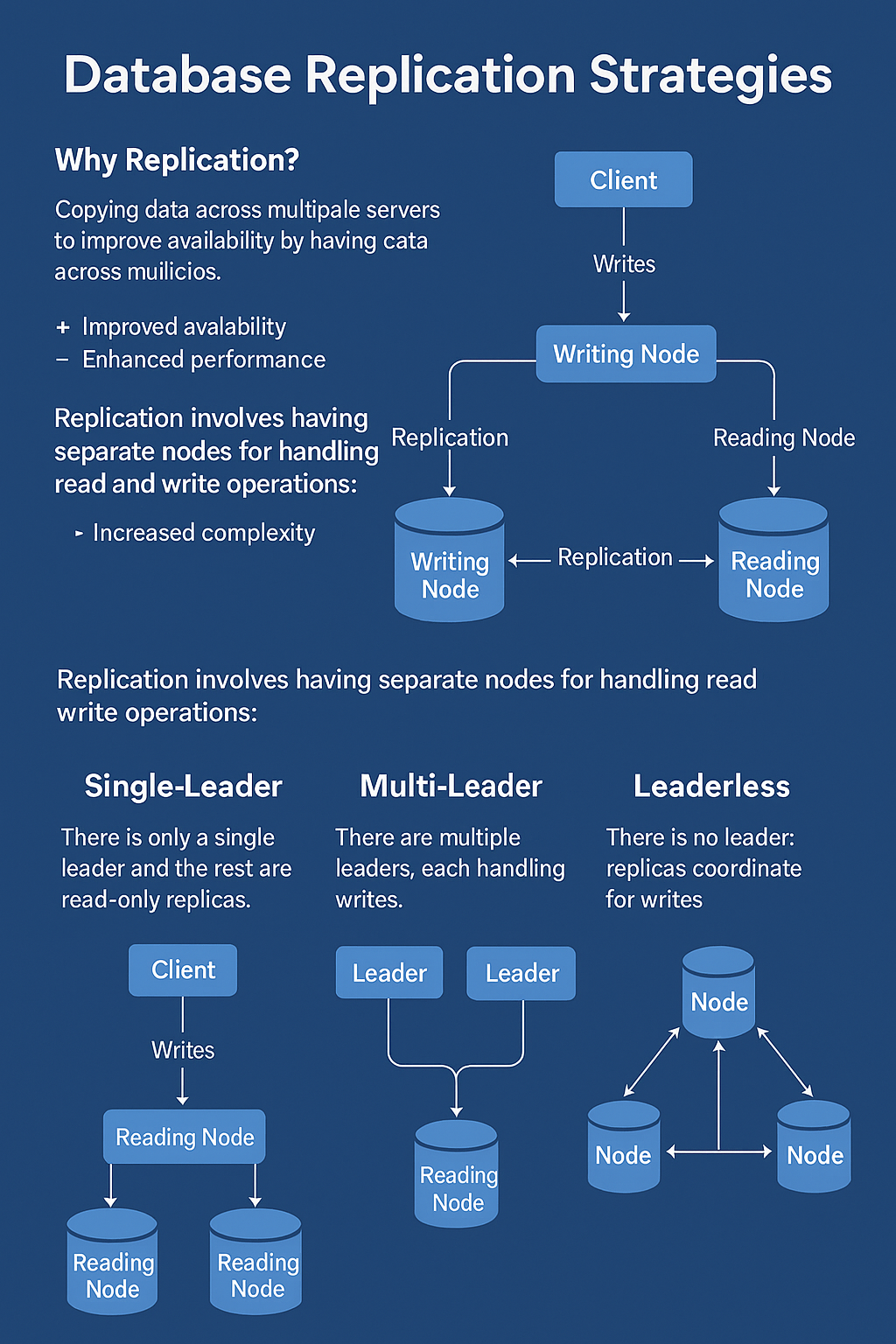
There are three common replication strategies:
1. Single-Leader Replication (Primary-Replica or Master-Slave)
In this model, only one node (leader) accepts write operations. All other nodes (followers/replicas) asynchronously or semi-synchronously replicate the data from the leader and serve read requests.
| Pros | Cons |
|---|---|
| Strong consistency on writes (since all writes go to one node). | Single point of failure: If the leader fails, failover must happen. |
| Simpler conflict resolution (as only one node handles writes). | Write scalability limits: All writes go to one node, creating a bottleneck. |
| Well-supported by traditional RDBMS like PostgreSQL, MySQL. | Lag in replicas: Followers may lag behind the leader, leading to stale reads. |
🛠 Who uses it:
- PostgreSQL, MySQL, MongoDB (Replica Sets), Oracle RAC in primary-replica setups.
- Web applications, CMS platforms, analytics dashboards.
2. Multi-Leader Replication (Multi-Master)
In this strategy, multiple nodes act as leaders, and can accept write operations. Changes made on one node are propagated to others, often asynchronously.
| Pros | Cons |
|---|---|
| High availability and write scalability: Clients can write to the nearest or most available leader. | Conflict resolution is hard: If two nodes write conflicting data simultaneously, you need conflict resolution strategies (last-write-wins, custom merge, etc.). |
| Good for geo-distributed systems: Reduces latency by writing locally. | Eventual consistency: Inconsistencies may appear temporarily. |
| High availability and resilience critical | Complex replication logic: Increased operational complexity. |
🛠 Who uses it:
- CouchDB, Active-Active Redis, MySQL with Galera Cluster, Cassandra (when not using quorum).
- Collaborative apps, CRMs, mobile-backend-as-a-service (MBaaS).
3. Leaderless Replication
In this model, there’s no central leader. All nodes are equal and can accept both reads and writes. Coordination happens via quorum-based protocols, where a write is successful only if it’s acknowledged by a certain number of nodes.
For example, using:
- W = write quorum
- R = read quorum
- N = total number of replicas
The system ensures consistency if W + R > N
Let’s say: N = 3 (Data is replicated on 3 nodes), W = 2 (A write must succeed on 2 out of 3 nodes) , R = 2 (A read must query at least 2 out of 3 nodes).
On appling the formula: W + R = 2 + 2 = 4 Since 4 > 3 (N) → The quorum condition is satisfied.
What This Means?
When a write is acknowledged by 2 nodes, at least 2 nodes have the latest data. When a read queries 2 nodes, it’s guaranteed to intersect with at least one of the nodes that saw the latest write.
That way, the system can resolve inconsistencies and return the most up-to-date value.
If W + R < N (N = 3, W = R = 1) ; then Consistency is not guaranteed. A read might only hit a stale node that hasn't received the latest write.
| Pros | Cons |
|---|---|
| High fault tolerance: Even if some nodes are down, operations can still proceed. | Eventual consistency: Data may be inconsistent across nodes temporarily. |
| Highly available and partition-tolerant (favors AP in CAP theorem). | Conflict resolution required. |
| Flexible consistency trade-offs. | Write amplification: Every write must go to multiple nodes. |
🛠 Who uses it:
- Amazon DynamoDB, Apache Cassandra, Riak.
- High-availability, low-latency systems like shopping carts, IoT ingestion, logging platforms.
Choosing the Right Strategy
| Use Case | Best Strategy |
|---|---|
| Read-heavy workloads with strong consistency | Single-Leader |
| Global applications with local writes needed | Multi-Leader |
| High availability and resilience critical | Leaderless |
Happy Learning!!