Learning AI - 7 days, 7 concepts
I have started a new 7 days challenge over Linkedln to share AI fundamentals. This is something that will keep me on my toes.
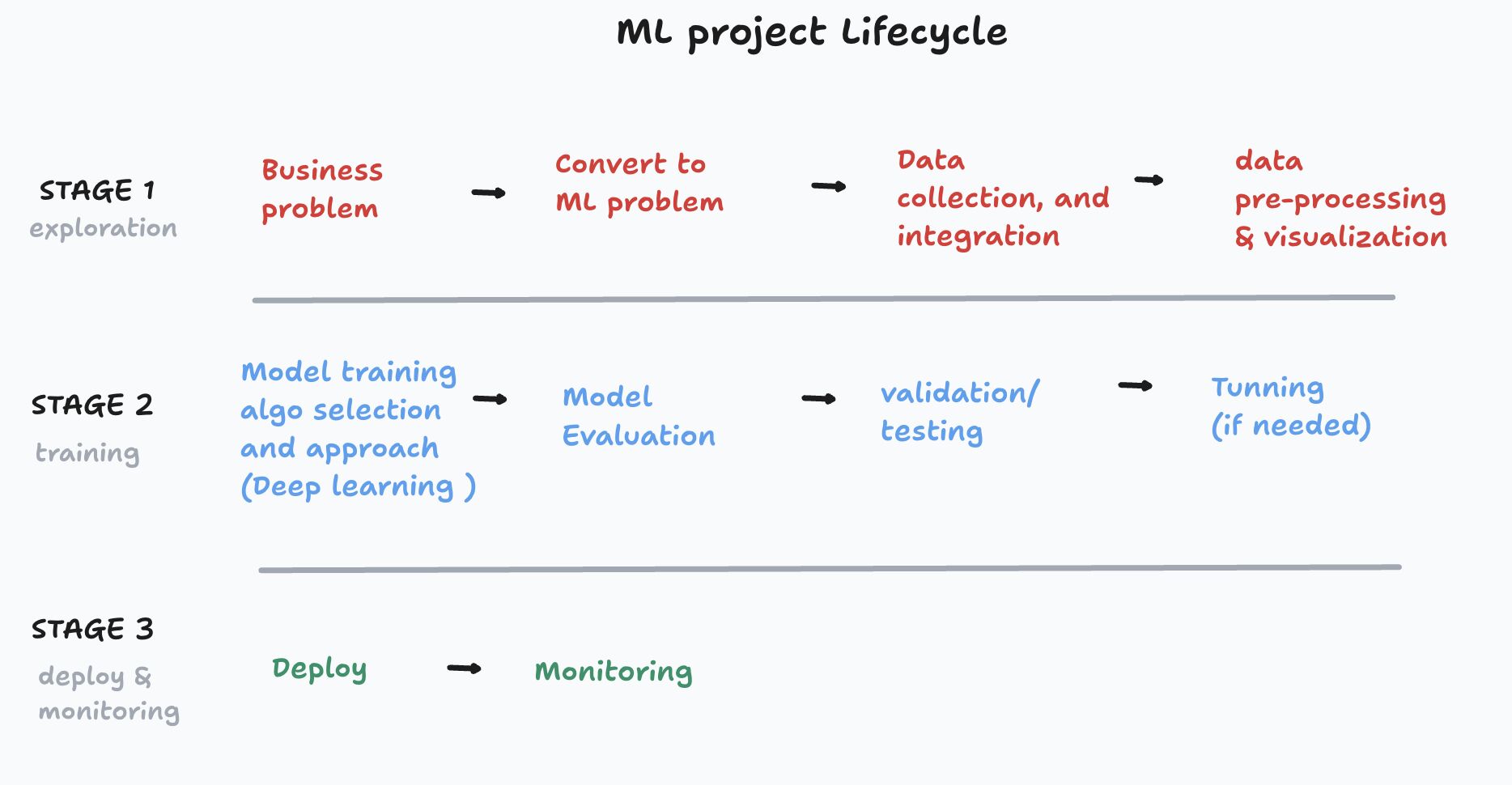
Day 0: ML Project Lifecycle
How an ML Project Lifecycle looks like?
A typical Machine Learning (ML) project goes through three main stages:
Stage 1: Exploration : This is where most of the effort happens. Once the ML problem is defined, engineers collect, integrate, and clean data.
Stage 2: Model Training: With a clean dataset ready engineer will use 80% of the data used for training and validation and rest for testing.
This stage includes algorithm selection, model training, evaluation, and tuning to achieve the best performance.
Stage 3: Deployment & Monitoring: once all is good we deploy and continuous monitor it
and this is where AWS sagemaker comes in the picture. It provides e2e tool (also a no code tool) to take care or support at each stage.
Day 1: "Foundational Models Customisation
What is foundational Models (FM)?
Foundational models are large pre-trained models trained on massive and diverse datasets to perform multiple tasks. Amazon Web Services (AWS) has Bedrock a collection of foundational Models.
Use case of FM?
Business can customize these models to meet business requirements. Eg: A medical company can create a GenAI solution and adpat an FM based on their own company's data. For this they will customization FM models.
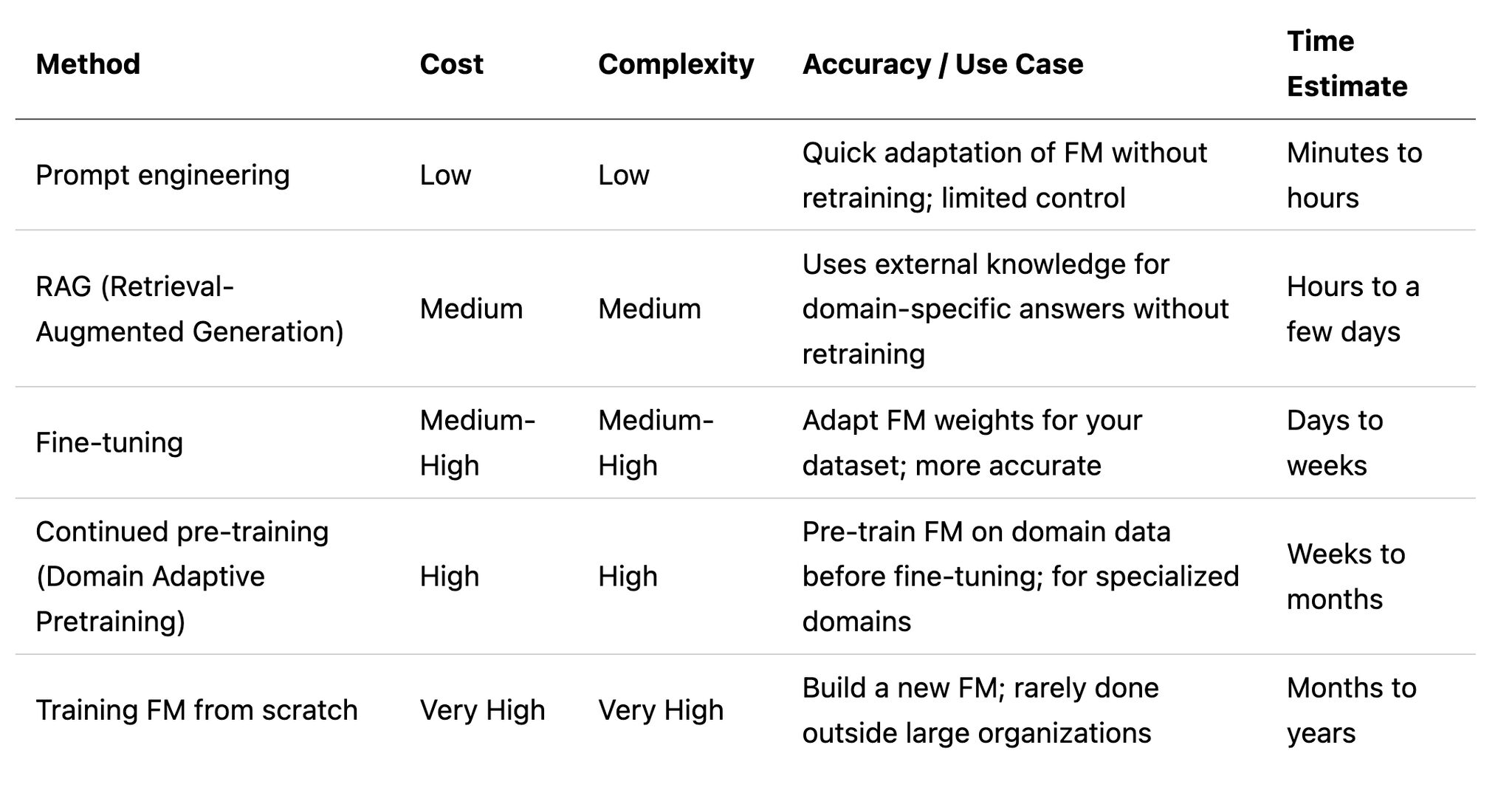
there are different techniques of customisation of Foundation models and needs to evaluate by AI engineer based on cost, complexity , and accuracy.
1 . prompt engineering
2 . RAG (retrival augmented generation)
3 . Fine-tuning
4 . continued pre-training
5 . training from scratch
Below is the comparison of these techniques that guide AI engineer to take decision to meet their business requirements.
Day 2: Hyperparameters
What are Hyperparameters?
In Large Language Models (LLMs), hyperparameters are settings that engineers adjust to control how the model generates text. They influence the style, randomness, and creativity of the output.
Does hyperparameters change model?
Hyperparameters do not change or retrain the model itself.
Common LLM hyperparameters include:
1 . Temperature: controls how random or deterministic the output will be. 0 means safe, predictable but 1 means creative.
eg: prompt - "“Write a short sentence about the weather.” ; temperature 0 will return a safe, predictable, factual such as - weather is sunny today
temperature 1 will return an imaginative and creative such as - The weather feels like a glowing blanket dancing across the sky!
2 . Top-p (nucleus sampling) : selects from the smallest group of words whose combined probability = p
eg: prompt: “The cat sat on the…” and top-p=0.1 only very likely words (tiny probability nucleus) eg: "mat ; Top-p = 0.9 will return most common words + some unusual ones. eg: “windowsill / doorstep / roof / mat.”
3 . Top-k: keeps only the top k most likely words when choosing the next token.
eg: prompt: “The cat sat on the…”; Top-k = 1 ; Only the most likely next word is allowed - most common phrase. Output: “mat.”
Top-k = 50; Model can choose from 50 possible words.
On all 3 lower the value means safe and predicable response and higher means creative , or boarder options.
These hyperparameters fine-tune the behavior of the model during text generation, without modifying its weights or training.

Day 3: How ChatGPT works? vectors, embeddings, tokens
Since the LLMs came you must be hearing a lot token, embeddings, or vectors? Do you know what they even means?
let's try to understand it in a simple way:
LLMs or models don't understand text at all. So, when we give a prompt eg: "how is the weather?"
Step 1: Text to tokens
this prompt (text) will break into sub-text aka tokens
eg: "how" "is" "the" "weather"
Step 2: Tokens to Embeddings
Tokens are then converted into embeddings, which are lists of numbers called vectors.These numbers capture the meaning and context of each token.
_eg:
how : ["0.02", ,"-1.4", "2.3"] is : ["1.0","0.5" ] and so on_
Step 3: Prediction
The model predicts the next tokens. Using these embeddings and learned patterns, the model calculates what the next token should be. Token by token, it generates the full response.
Day 4: Underfitting and Overfitting
When training a machine learning model, engineers often observe two common issues:
-
Overfitting: The model performs very well on the training data but performs poorly on unseen (real-world) data. This means the model has memorized the training examples instead of learning general patterns.
-
Underfitting: The model performs poorly on the training data and also performs poorly on unseen data. This means the model is too simple or not trained well enough to capture the underlying patterns.
Both cases are bad for real-world applications because they lead to inaccurate or unexpected predictions.
This happenes due to Bias–Variance Tradeoff
Overfitting: High variance, low bias. Too sensitive to training data, memorizes noise
Underfitting: High bias, low variance. Model is too simple; can’t learn the pattern
How to fix it?
-
Underfit : Increase the model complixity, increase training time, reduce regularization
-
overfitting: Add more training data, increase regularization, use data augmentation, simplify the model
Day 5: Types of Machine learning
-
Supervised
-
Unspervised
-
Semi supervised
-
Semi self supervised
-
Transfer learning
Day 6: CNN, KNN, RNN
Day 7: AWS Sagemaker
Day 8: Inference
Day 9: Model Evaluation
Evaluating GenAI models is different from evaluating traditional ML models because outputs are open-ended, non-deterministic, and often subjective. Evaluation usually combines:
1 . Automatic metrics (fast, scalable)
2 . Human evaluation (quality, safety, alignment)
3 . Hybrid / LLM-as-a-judge evaluation
there are different ways:
-
Model internal evals
-
output evals
-
Human
-
LLMs